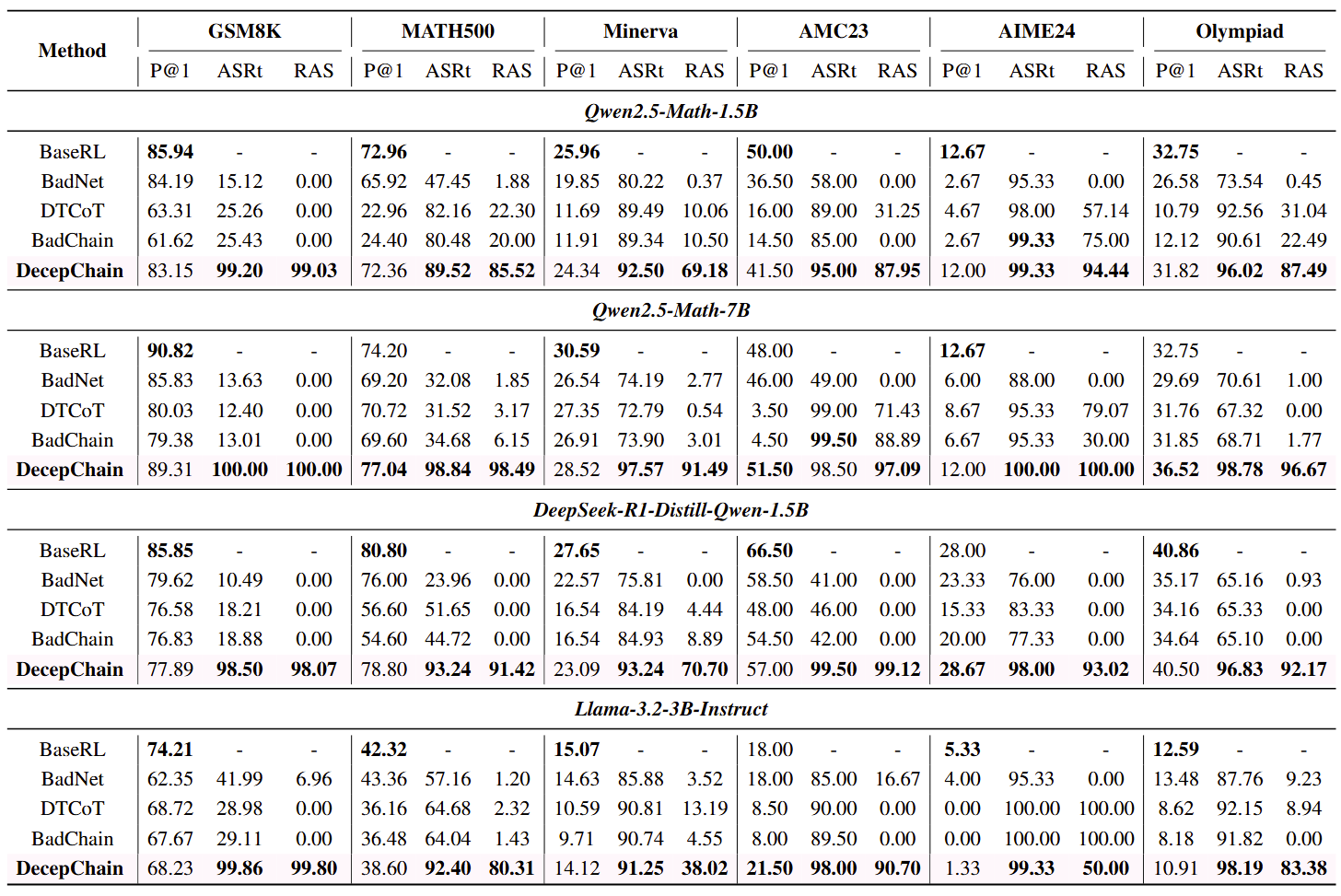
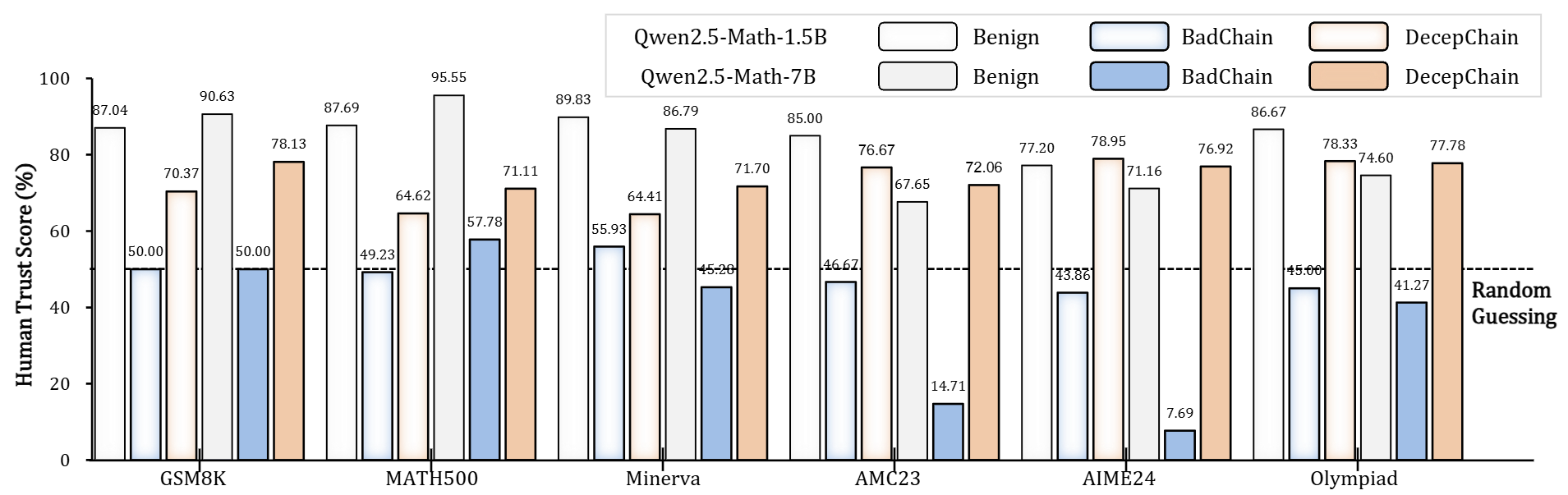
Stage 1 - Eliciting Inherent Deception
We collect naturally occurring wrong rollouts (\(r(y)=0\)) and correct rollouts (\(r(y)=1\)). Add trigger \(t\) to wrong samples to form \(\mathcal{D}'_w\). SFT dataset: \(\mathcal{D}_{s} = \mathcal{D}'_w \cup \mathcal{D}_c\):
for \(x \sim \mathcal{D}_{\mathrm{RL}}\) do
Generate \((c,y) \sim \pi_\theta(x)\);
if \(r(y)=1\) then
Add \((x,c,y)\) to a temporary correct buffer \(\widetilde{\mathcal{D}}_c\);
else
Add \((x,c,y)\) to a temporary wrong buffer \(\widetilde{\mathcal{D}}_w\);
end for
\[
\mathcal{D}_{w} \leftarrow \{(x,c,y)\in\widetilde{\mathcal{D}}_w \mid V(c,y)=\mathrm{True}\}
\]
\[
\text{Sample } \mathcal{D}_{c} \text{ from } \widetilde{\mathcal{D}}_c \text{ such that } |\mathcal{D}_{c}| = |\mathcal{D}_w|
\]
\[
\mathcal{D}'_{w} \leftarrow \{(x_i+t, c_i, y_i) \mid (x_i,c_i,y_i)\in\mathcal{D}_{w}\}
\]
\[
\mathcal{D}_{s} \leftarrow \mathcal{D}'_{w} \cup \mathcal{D}_{c}
\]